Introduction
The tags2con dataset has been manually created by a group of human annotators that linked del.icio.us tags to their real meaning.
A subset of a delicious dump has been used to create the tags2con dataset, a set of 1681 user-bookmarks pairs have been selected and all the tags used by these pairs have been manually cleaned and disambiguated to WordNet synsets.
The dataset we have built includes annotations from users which have less than 1000 tags and have used at least ten different tags in five different website domains. This upper bound was decided considering that Delicious is also subject to spamming, and users with more than one thousand tags could potentially be spammers or machine generated tags as the original authors of the crawled data assumed.
Furthermore, only user-bookmark pairs that have at least three tags (to provide diversity in the golden standard), no more than ten tags (to allow timely manual evaluation) are selected. Only URLs that have been used by at least ten users are considered in order to provide enough overlap between users. After retrieving all the user-bookmark pairs that comply with the previously mentioned constraints, we randomly selected 1681 pairs with the following method: 500 pairs were selected purely at random, 1181 pairs were selected randomly at equal distribution in the pairs that overlaped with one of the following DMOZ topics: Top/Home/Cooking, Top/Recreation/Travel or Top/Reference/Education. Table 1 summarizes the characteristics of the resulting subset of the dataset.
| Item | Count |
|---|---|
| <r, u> pairs | 1681 |
| total number of tags | 7323 |
| average number oftags per pair | 4.35 |
| unique tags | 1569 |
| unique URLs | 739 |
| unique users | 1397 |
| website domains | 603 |
Each tag has been split into lemmatized tokens and each of them has then been linked to its meaning in the WordNet 3.0 ontology
Browsing the Dataset
All resource identifiers defined by this dataset are dereferenceable.
The dataset is described using VOID, either in N3 format or in RDF format.
Some examples of the dataset can be found at:
- the hometheater tag (n3, Ontology Browser)
- the Home Theater concept (n3, Ontology Browser)
- the user 560124 (n3, Ontology Browser)
- the bookmark 224106 of user 560124 (n3, Ontology Browser)
We also provide some entry points to the set of instances in the dataset:
- All Tags (n3, Ontology Browser)
- All Bookmarks (n3, Ontology Browser)
- All Users (n3, Ontology Browser)
- All Concepts (n3, Ontology Browser)
License

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.
Dataset Vocabulary
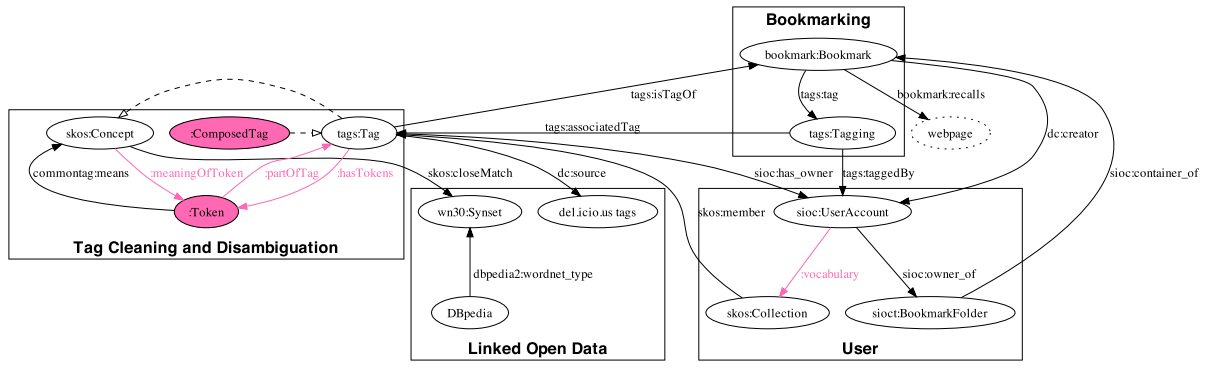
Figure 1: RDF Mapping for the Semantified Delicious dataset.
While the Newman's tagging ontology and the SCOT extension can represent the tripartite graph model of folksonomies, they do not discriminate between a tag and a concept.
In Figure 1, we propose an extension to the Newman's ontology where a tags:Tag can be split in a number of tags2con:Token that then link to the actual semantic in a knowledge organisation system (in this case a SKOS:Concept) that can be used in reasoning. In this proposal, for compatibility with the existing RDF models that widely use the Newman's tags:Tag class, we also use this one. However, it is our belief that this creates a confusion between the linguistic layer of the folksonomy and its conceptual layer that can lower the accuracy of reasoning services based on this data. Thus, we would recommend to drop such compatibility in the future.
In addition to the tags2con extension (rdf, n3, Ontology Browser), the main ontologies that we use to distribute the dataset are:
Agreement
In order to guarantee the correctness of the assignment of tag splits and tag token senses, two different validators validated all tags of each user-bookmark pair.
The "agreement without chance correction" between users in the task of disambiguation of tokens is of 0.81.
Some Statistics
In the current distribution, we only include the annotations were two validators have agreed on the sense and split of the tags.
The current dataset contains:
- 1474 Bookmakrs
- 1193 Users
- 2832 Tags
- 651 Concepts
- 85908 triples
Authors
This dataset was thought, designed, annotated and distributed by:
For any request relating to this dataset, please contact andrews@disi.unitn.it.
Publications
You can cite:
- Andrews, Pierre and Pane, Juan and Zaihrayeu, Ilya (2011) Semantic Disambiguation in Folksonomy: a Case Study; in Advanced Language Technologies for Digital Libraries, Springer's Lecture Notes on Computer Science (LNCS) Hot Topic subline, Vol 6699; pp 114-134, DOI: 10.1007/978-3-642-23160-5_8. (bibtex,mendeley) Also available as a Technical Report DISI-10-063, Ingegneria e Scienza dell'Informazione, University of Trento.
Linked Open Data (LOD) Cloud
The dataset that we are distributing here is following the Linked Data principles and also tries to fulfill the requirements of the LOD Cloud:
- There must be resolvable http:// (or https://) URIs — All resources are available through http://.
- They must resolve, with or without content negotiation, to RDF data in one of the popular RDF formats (RDFa, RDF/XML, Turtle, N-Triples) — the dataset is available as RDF/XML and N-Triples.
- The dataset must contain at least 1000 triples — The dataset currently contains 18675 triples and a planned update should add almost double this.
- The dataset must be connected via RDF links to a dataset that is already in the diagram. This means, either your dataset must use URIs from the other dataset, or vice versa. We arbitrarily require at least 50 links — the dataset links to the WordNet 3.0 resources, with around 262 links.
- Access of the entire dataset must be possible via RDF crawling, via an RDF dump, or via a SPARQL endpoint — The dataset is availlable through RDF crawling and an RDF dump can be provided on request.
In addition, the tags2con dataset has been registered on CKAN.
Tools for Annotation
Upcoming: The tools that were used to create this dataset will be available as open source soon


